


- Published on
Nodejs에 대한 잘못된 상식 몇가지
- Author
- Name
- yceffort
Nodejs는 2009년 만들어진 이래로 많은 사랑을 받고 있는데, 아마도 그 이유 중 하나는 자바스크립트로 작성할 수 있다는 사실 일 것이다. nodejs는 그 이름에서 느낄 수 있는 것처럼, 서버사이드 애플리케이션을 자바스크립트로 작성할 수 있도록 만들어졌다. 그렇다고 해서, nodejs가 100% 자바스크립트로 이루어져있는 것은 아니다.
자바스크립트는 싱글 스레드로, 언어가 처음 디자인 되었을 때는 서버사이드에서 실행되기에는 부적절하게 디자인 되어 있었다. 그러나 구글의 고성능 자바스크립트 엔진인 V8이 등장과, 비동기 I/O 를 수행하는 libuv의 탄생, 그리고 몇가지 기술들이 추가되면서 자바스크립트로 몇천개의 소켓 연결이 일어나는 서버를 구현할 수 있게 됐다.

이미 몇번씩이나 본 nodejs의 구조
nodejs는 위 그림에서 볼 수 있는 것처럼 여러가지 컴포넌트로 구성된 대규모 플랫폼이다. 그러나 nodejs 내부 동작에 대한 이해가 부족하기 떄문에, 많은 개발자들이 잘못된 가정을 가지고 개발을 하며, 이로인해 추적하기 어려운 버그를 만들고 심각한 성능 문제로 이어지는 애플리케이션을 만들어 낸다. 여기서 몇가지 nodejs의 잘못된 이해에 대해 짚고 넘어가려고 한다.
Table of Contents
- EventEmitter와 EventLoop간에 관계가 있다?
- 콜백을 받는 모든 함수는 비동기로 실행된다?
- CPU 집약적인 함수는 EventLoop를 블로킹한다.
- 모든 비동기 작업은 쓰레드 풀에서 실행된다?
- NodeJS는 CPU 집약적인 작업을 하는 애플리케이션에서 사용하면 안된다?
EventEmitter와 EventLoop간에 관계가 있다?
Nodejs EventEmitter는 nodejs 애플리케이션을 만들다보면 많이 사용하게 되는 라이브러리다. 그러나 이름만 비슷할 뿐, EventEmitter와 EventLoop사이에는 아무런 관계가 없다.
Nodejs의 EventLoop는 Nodejs의 비동기, 논블로킹 I/O 메커니즘을 처리하는 핵심적인 부분이다. EventLoop는 다양한 유형의 비동기 이벤트를 특정 순서로 처리한다. EventLoop에 대한 글은 인터넷에 차고 넘치니.. 더이상 자세한 설명은 생략한다
- https://yceffort.kr/2019/09/06/javascript-event-loop
- https://yceffort.kr/2020/10/how-node-js-works
- https://blog.insiderattack.net/event-loop-and-the-big-picture-nodejs-event-loop-part-1-1cb67a182810
반면에 Nodejs의 EventEmitter는 특정 이벤트에 리스너 함수를 달아서, 이벤트가 발생 했을 때 이를 캐치할 수 있도록 만들어진 api다. 이 동작은 일반적으로 이벤트 리스너가 원래 등록된 이벤트 헨들러보다 나중에 호출되기 때문에 비동기처럼 보인다.
그러나 EventEmitter의 인스턴스는 EventEmitter 인스턴스 자체내에서 이벤트와 연결된 모든 이벤트와 리스너를 추적한다. 따라서 EventLoop의 큐를 사용하는 것이 아니다. 이 정보가 저장되는 데이터 구조는, 단순히 이벤트 이름이 있는 이벤트 객체일 뿐이다. 그리고 그 값은 이벤트 리스너 함수들이 들어가 있는 배열일 뿐이다.
대략 이런 느낌 https://yceffort.kr/2020/10/implement-event-emitter
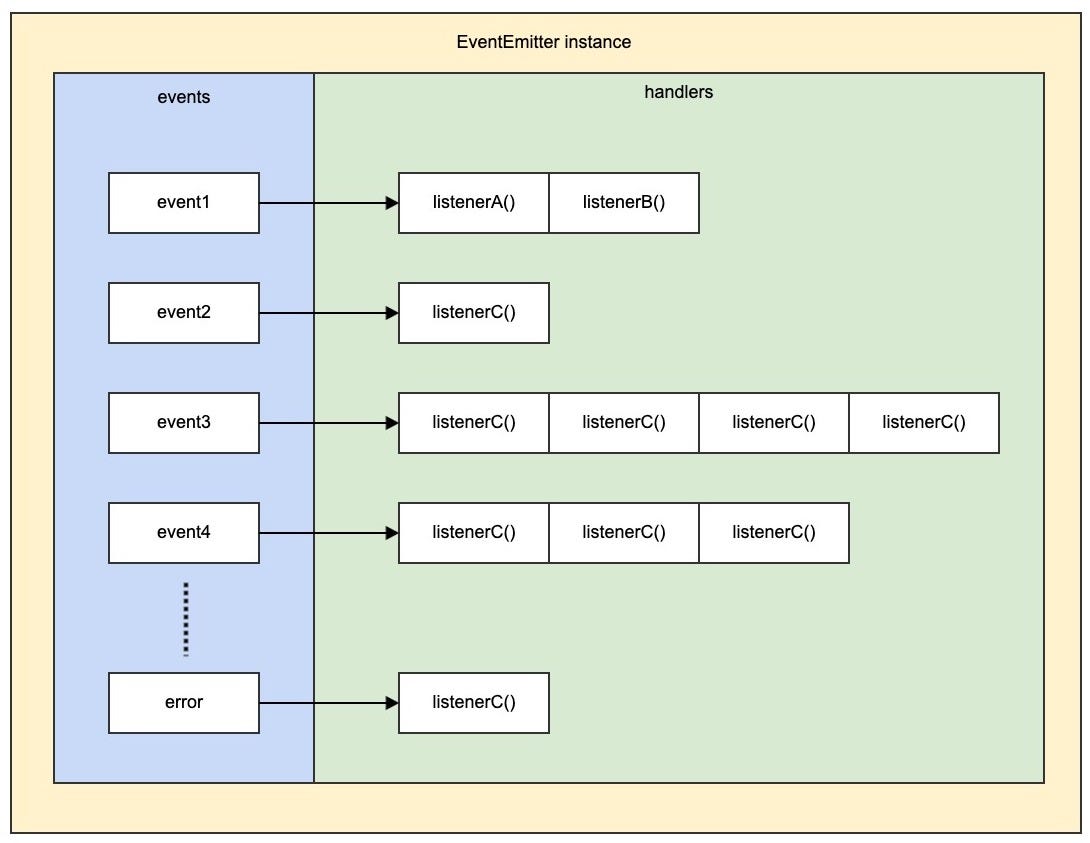
EventEmitter의 emit함수가 호출되면, emitter는 동기적으로 등록되어 있는 리스너 함수를 순차적으로 호출한다.
const EventEmitter = require('events')
const myEmitter = new EventEmitter()
myEmitter.on('myevent', () => console.log('handler1: myevent was fired!'))
myEmitter.on('myevent', () => console.log('handler2: myevent was fired!'))
myEmitter.on('myevent', () => console.log('handler3: myevent was fired!'))
myEmitter.emit('myevent')
console.log('I am the last log line')
handler1: myevent was fired!
handler2: myevent was fired!
handler3: myevent was fired!
I am the last log line
EventEmitter가 동기적으로 모든 이벤트 핸들러를 호출하기 때문에, I am the last log line는 모든 리스너 함수가 실행되기 전까지 출력되지 않는다.
콜백을 받는 모든 함수는 비동기로 실행된다?
함수가 동기인지 비동기 인지는 함수가 실행중에 비동기 리소스를 생성하는지 여부에 따라 달려 있다. 따라서 아래에 주어진 함수를 사용하고 있다면, 함수가 비동기인지 여부를 판단할 수 있다.
- 자바스크립트/Nodejs의 네이티브 비동기 함수:
setTimeoutsetIntervalsetImmediateprocess.nextTick... - nodejs만으이 네이티브 비동기 함수:
child_processfsnet... PromiseAPI (asyncawait)- c++ addon으로 부터 호출되어 비동기로 작성된 함수 becrypt
콜백함수를 argument로 받아도 함수가 비동기화 되는 것이 아니다. 그러나 일반적으로 비동기 함수는 콜백을 마지막 인수로 받는다. (Promise를 리턴하기 위해 랩핑되지 않는 한) 콜백을 받고, 그 결과를 콜백을 전달하는 패턴을 Continuation Passing Style이라고 한다. 이 스타일을 하면, 100% 동기함수를 작성할 수 있다.
const sum = (a, b, callback) => {
callback(a + b)
}
sum(1, 2, (result) => {
console.log(result)
})
동기 함수와 비동기 함수는 실행 중에 스택을 사용하는 방법에 있어 큰 차이가 존재한다. 동기 함수는 스택이 반환될 떄 까지, 다른 사용자가 스택을 점유할 수 없도록 하여 전체 실행기간 동안 스택을 점유 한다. 그러나 비동기 함수는 일부 비동기 작업을 예약한 채로 즉시 반환되므로, 스택에서 제거된다. 예약된 비동기 작업이 완료되면 제공된 콜백이 호출되고, 이 콜백 함수가 다시 스택을 점유하게 된다. 이 시점에서 비동기 작업을 시작한 함수는 이미 리턴되어버렸으므로 스택에서 더이상 사용할 수가 없다.
그렇다면, 아래 함수는 동기일까 비동기 일까?
function writeToMyFile(data, callback) {
if (!data) {
callback(new Error('No data!'))
} else {
fs.writeFile('myfile.txt', data, callback)
}
}
정답은, data로 무슨 값이 오느냐에 따라 다르다. data가 falsy 한 값이라면 콜백은 즉시실행되어 에러를 뱉는다. 이 경우, 함수는 100% 동기로 작동되어 어떠한 비동기 작업도 수행하지 않는다.
반대로, data가 truthy한 값이라면, data가 myfile.txt에 쓰여지기 시작하고, I/O작업이 끝나게 되면 콜백이 실행된다. 이 경우 파일 I/O 작업이 수행되므로, 100% 비동기다.
함수를 이따위(?)로 일관적이지 못하게 작성하는 것(= 비동기일수도 동기일수도 있게)은 애플리케이션이 함수의 동작을 예측할 수 없기 때문에 매우 별로다.
function writeToMyFile(data, callback) {
if (!data) {
process.nextTick(() => callback(new Error('No data!')))
} else {
fs.writeFile('myfile.txt', data, callback)
}
}
process.nextTick는 콜백함수 호출을 지연시켜 비동기로 만드는데 사용할 수 있다. 물론, setImmediate를 사용할 수도 있다. 그러나 process.nextTick이 setImmediate보다 더 높은 우선순위를 가지고 있어 빠르다.
CPU 집약적인 함수는 EventLoop를 블로킹한다.
많은 사람들이 CPU 집약적인 작업은 Node.js의 EventLoop를 블로킹한다고 믿고 있다. 이는 어느정도는 사실이지만, EventLoop를 차단하지 않는 일부 함수들이 있기 때문에 100% 사실이 아니다.
일반적으로, 암호화/압축 작업은 CPU를 많이 잡아 먹는다. 이러한 이유로, 특정 crypto 함수나 zlib함수는 비동기 버전이 있으며, 이 함수는 EventLoop를 차단하지 않도록 libuv 쓰레드 풀에서 계산을 수행한다. 그 함수들의 목록은 아래와 같다.
crypto.pbkdf2()crypto.randomFill()crypto.randomBytes()zlib의 모든 비동기 함수
그러나 순수 자바스크립트를 사용하여 libuv 쓰레드 풀에서 CPU 집약적인 작업을 수행할 수 있는 방법은 없다. 그러나 libuv 스레드 풀에서 작업을 예약할 수 있는 C++ addon을 직접 작성할 수는 있다. CPU 집약적인 연산을 수행하고, CPU 바운더리 연산을 위한 비동기 API를 구현하기 위해 C++ addon을 사용하는 이와 같은 라이브러리에는 brcypt가 있다.
모든 비동기 작업은 쓰레드 풀에서 실행된다?
최신 운영체제들은 Event Notification(linux의 epoll, Macos의 kqueue, 윈도우의 IOCP)을 사용하여 네트워크 IO작업을 위한 네이티브 비동기화를 용이하게 지원하는 커널을 내장하고 있다. 따라서 네트워크 IO는 libuv쓰레드 풀에서 실행되지 않는다.
그러나 파일 IO는 운영체제 전반에 있어서, 경우에 따라는 운영체제 버전에 따라서 상이한 경우가 많다. 따라서 일반화된 플랫폼 독립 File IO api를 만드는 것이 매우어렵다. 따라서 파일 시스템 작업은 일관된 비동기 API를 만들기 위해서 libuv 스레드 풀에서 수행된다.
dns 모듈 내에 있는 dns.lookup() 함수도 마찬가지로 libuv스레드 풀에서 실행된다. 이 함수를 사용하여 도메인 이름을 IP 주소로부터 확인하는 것은 플랫폼 종속적인 작업이며, 이작업은 100% 네트워크 IO가 아니기 때문이다.
NodeJS는 CPU 집약적인 작업을 하는 애플리케이션에서 사용하면 안된다?
정확히 말하면, 이는 과거까지는 사실이었지만 이제 worker thread가 도입되면서 가능해졌다. 따라서 CPU 집약적인 작업을 처리하는 프로덕션 애플리케이션에서 Node.js를 사용하기에 적합해졌다.
각 Nodejs의 워커 쓰레드는 자체 v8 런타임의 복사본, Event Loop, libuv 스레드풀을 가진다. 그러므로 CPU 집약적인 블로킹 작업을 하는 하나의 worker thread는 다른 worker thread에 영향을 주지 않게 된다.
https://yceffort.kr/2021/04/nodejs-multithreading-worker-threads
그러나 worker thread를 원활하게 지원하는 IDE는 현재 없는 것으로 보인다. 일부 IDE의 경우, 기본 main worker가 아닌 worker thread에 디버거를 연결하는 것을 지원하지 않는다. 그러나 현재 점차 많은 개발자들이 비디오 인코딩과 같은 CPU 집약적인 작업의 지원을 위해 worker thread 채택을 시작하기 때문에 점차 성숙할 것으로 보인다.